원문: http://kelp.or.kr/korweblog/stories.php?story=02/03/31/9629811
gcc는 예전에는 GNU C Compiler의 약자였으나 지금은 GNU Compiler Collection의 약자로
다양한(?) 언어의 컴파일러들의 집합체이다. gcc는 한마디로 GNU에서 개발된 ANSI C 표준을 따르는 C 언어 컴파일러라고
말할 수 있다. gcc는 ANSI C 표준에 따르기는 하지만 ANSI C 표준에는 없는 여러 가지 확장 기능이 있다. 또한
gcc는 통합개발환경(IDE)을 가지고 있지 않은 command line 컴파일러이다. 옛날 Turbo-C를 주로 사용해 보셨던
분들은 tcc.exe와 비슷하다고 생각하면 된다.
(*) -v 옵션
현재 사용되고 있는 gcc의 버전을 나타내는 옵션이다. 특정 소프트웨어 패키지를 컴파일하기 위해 어느 버전 이상의 gcc를 쓰도록 권장하는 경우가 있는데 시스템에 깔려있는 gcc의 버전을 파악하려고 할때 사용한다.
이제 직접 프로그램 하나를 컴파일하면서 설명하도록 하겠다. 아래는 hello.c의 소스이다.
#include〈stdio.h〉
int main()
{
printf(“hello gccn”);
return 0;
} |
$ gcc -o hello hello.c
로 컴파일하면 실행파일 hello가 만들어진다.
(*) -o 파일이름 옵션
gcc의 수행 결과 파일의 이름을 지정하는 옵션이다. 위의 예제를 단순히
$ gcc hello.c
로 컴파일 하면 hello라고 하는 실행파일이 만들어 지는 것이 아니라 보통의 경우 a.out이라는 이름의 실행파일이 만들어진다.
-o hello 옵션을 줌으로써 결과물을 hello라는 이름의 파일로 만들어지게 하였다.
위의 컴파일 과정을 외부적으로 보기에는 단순히 hello.c파일이 실행파일 hello로 바뀌는 것만 보이지만 내부적으로는 다음과 같은 단계를 거쳐 컴파일이 수행된다.
(1) C Preprocessing
(2) C 언어 컴파일
(3) Assemble
(4) Linking
C
Preprocessing은 C 언어 배울 때 배운 #include, #define, #ifdef 등 #으로 시작하는 여러 가지를
처리해 주는 과정이다. 그 다음 C 언어 컴파일은 C Preprocessing이 끝난 C 소스 코드를 assembly 소스코드로
변환하는 과정이다. Assemble은 그것을 다시 object 코드(기계어)로 변환하고 printf()함수가 포함되어 있는
라이브러리와 linking을 하여 실행파일이 되는 것이다.
위의 네 가지 과정을 모두 gcc라는 실행파일이 해 주는
것일까? 겉으로 보기에는 그렇게 보일지 모르지만 실제로는 gcc는 소위 말해 front-end라고 하여 껍데기에 지나지 않고
각각을 해 주는 다른 실행파일을 gcc가 부르면서 수행된다.
C Preprocessing을 전담하고 있는 실행파일은
cpp라고 하여 /usr/bin 디렉토리와 /usr/lib/gcc-lib/i386-redhat-linux/egcs-2.95.12
디렉토리(당연히 gcc버전과 시스템에 따라 디렉토리 위치가 다르다. gcc -v로 확인하길 바란다.)에 존재한다. C 언어
컴파일은 cc1이라는 실행파일이 담당하는데 /usr/lib/gcc-lib/i386-redhat-linux/egcs-2.95.12
디렉토리에 존재한다. Assemble과 linking은 각각 as와 ld라는 실행파일이 담당하고 /usr/bin 디렉토리에
존재하는 파일이다. (참고 : 시스템에 따라 /usr/bin이 아니라 /bin또는 /usr/local/bin 디렉토리에 존재할
수도 있다.)
gcc라는 실행파일이 하는 일을 정리해 보면 다음과 같다.
(1) 사용자에게 옵션과 소스 파일명들의 입력을 받는다.
(2) 소스 파일명의 확장자를 보고 어떤 단계를 처리해야 할지 결정한다.
(3) 사용자의 옵션을 각각의 단계를 맡고 있는 실행파일의 옵션으로 변경한다.
(4) 각각의 단계를 맡고 있는 실행파일을 호출(fork, exec)하여 단계를 수행하도록 한다.
=== C Preprocessing(cpp)
C
preprocessing을 우리말로 하면 "C 언어 전처리"라고 할 수 있을 것이다. 모든 C 언어 문법책에서 정도의 차이는
있지만 C preprocessing에 대한 내용을 다루고 있다. C preprocessing에 대한 문법은 C 언어 문법의 한
부분으로 가장 기본이 되는 부분이다. C preprocessing에 관한 문법은 모두 '#'으로 시작된다. '#' 앞에는 어떠한
문자(공백 문자 포함)도 오면 안된다. 하지만 대부분의 compiler가 '#'앞에 공백 문자가 오는 경우에도 처리를 한다.
== C preprocessing이 하는 일
(1) 입력 : C 언어 소스 코드
(2) 출력 : 전처리가 완료된 C 언어 소스 코드
(3) 하는 일
- 파일 포함(file inclusion - 헤더파일 및 기타파일)
- 매크로(macro) 치환
- 선택적 컴파일(conditional compile)
- 기타(#line, #error, #pragma)
cpp
는 C 언어 소스코드를 입력 받아서 C preprocessing에 관련된 문법 사항을 적절히 처리하고 결과로 C 언어 소스코드를
출력하는 프로그램이다. 입력은 작성된 C 언어 소스 코드이고, 출력으로 나온 C 언어 소스 코드에는 C preprocessing
문법에 관련된 어떠한 것도 남아있지 않는다. 즉, #define, #include 등을 찾을 수 없다. 남아 있는 정보가 있다면
file 이름과 줄수(line number)에 관한 정보이다. 그 이유는 추후의 컴파일 과정에서 에러가 날 때 그 정보를
이용해서 error를 리포팅할 수 있도록 하기 위해서이다. 그렇다면 C preprocessing을 직접 해보자.
$ gcc -E -o hello.i hello.c
결과로 hello.i라는 파일이 생긴다. 그 파일을 에디터로 열어보면 hello.c의 첫번째 줄에 있는 #include 를 처리한 결과가 보일것이다.
(*) -E 옵션
-E
옵션은 gcc의 컴파일 과정 중에서 C preprocessing까지만 처리하고 나머지 단계는 처리하지 말라는 것을 지시하는
것이다. 평소에는 별로 쓸모가 있는 옵션이 아니지만 다음과 같은 경우에 유용하게(?) 사용할 수 있다.
(1) C 언어 소스 코드가 복잡한 선택적 컴파일을 하고 있을 때, 그 선택적 컴파일이 어떻게 일어나고 있는지 알고 싶은 경우.
(2) preprocessing의 문제가 C 언어 에러로 나타날 경우. 다음과 같은 소스코드를 고려해 보자.
#define max(x, y) ((x) 〉(y) ? (x) : (y) /* 마지막에 ")"가 없다!!! */
int myMax(int a, int b)
{
return max(a, b);
} |
$ gcc -c cpperr.c
다음과 같은 에러가 난다.
cpperr.c: In function `myMax':
cpperr.c:4: parse error before `;'
cpperr.c파일의 4번째 줄에서 ';'가 나오기 전에 parse error가 났다. 하지만 실제 에러는 #define에 있었으므로 그것을 확인하려면 -E 옵션으로 preprocessing을 하여 살펴 보면 쉽게 알 수 있다.
(*) 참고 :
parse error before x(어떤 문자) 에러는 소스코드를 parsing 할 때 발생한 에러를 말한다.
parsing이란 syntax analysis(구문해석) 과정인데 쉽게 말하면 C 언어 소스코드를 읽어들여 문법적 구성요소들을
분석하는 과정이라고 할 수 있다. 보통 gcc에서 parse error라고 하면 괄호가 맞지 않았거나 아니면 ';'를 빼먹거나
했을 때 발생한다. 보통의 경우 before x라고하여 x라는 것이 나오기 전에 parse error가 발생하였음을 알려주기
때문에 그 x가 나오기 전에 있는 C 소스 코드를 잘 살펴보면 문제를 해결할 수 있다.
C
preprocessing의 문법과 나머지 C 언어의 문법과는 거의 관계가 없다. 관계가 있는 부분이 있다면 정의된 macro가
C 언어의 문법 상의 char string literal에는 치환되지 않는다는 정도이다. (좀 더 쉽게 이야기 하면 큰 따옴표
안에서는 macro 치환이 되지 않는다.) 또한 c preprocessing은 architecture dependent하지
않다. 즉, i386용으로 컴파일된 cpp를 다른 architecture에서 사용해도 무방하다. 조금 문제가 있을 수 있는
부분이 있다면 gcc의 predefined macro(i386의 경우 i386용 자동으로 define된다.)가 다를 수 있다는
점 뿐이다. 따라서 cpp를 C 언어 소스코드가 아닌 다른 부분에서 사용하는 경우도 있다. 대표적으로 assembly 소스
코드에서도 사용한다. assembler가 사용하고 있는 macro 문법이 c preprocessing의 macro문법 보다는
배우기 쉽기 때문이다.
이제 preprocessing이 하는 일에 대해서 좀더 알아 보자.
== 파일 포함(file inclusion)
#include 〈stdio.h〉
#include "config.h"
위
와 같이 많은 C 언어 소스코드에서 헤더 파일을 포함한다.〈〉와 ""의 차이는 기본적인 헤더파일과, 사용자 정의 헤더파일을
구분하는 정도이다. include한 헤더 파일은 default로 특정 디렉토리를 찾게 된다. Linux 시스템의 경우
/usr/include가 default 디렉토리이다. (실제로도 그곳에 stdio.h라는 파일이 있다.) 그 다음은 현재
디렉토리를 찾게 된다.(물론〈〉와 ""에 따라서 다르다.) 파일이 없으면 당연히 에러가 발생한다. gcc의 경우 다음과 같은
에러가 발생한다.
>>소스코드파일명:line number: 헤더파일명: No such file or directory
또는(LANG=ko일때)
>>소스코드파일명:line number: 헤더파일명: 그런 파일이나 디렉토리가 없음
그렇다면 include하고 싶은 파일이 default 디렉토리와 현재 디렉토리에 없으면 어떻게 할까? 그런 문제를 해결하기 위해서 다음과 같은 옵션이 존재한다.
(*) -Idir 옵션
여
기서 dir은 디렉토리 이름이고 -I와 디렉토리 이름을 붙여 써야 한다. 그럼 include한 헤더 파일을 그 디렉토리에서도
찾아 주게 된다. 당연히 옵션을 여러 번 다른 디렉토리 이름으로 사용할 수도 있어서 헤더 파일을 찾을 디렉토리를 여러 개로
지정할 수 있다. 꼭 알아 두어야 할 옵션이다.
(*) -nostdinc
이 옵션은 default 디렉토리(standard include 디렉토리)를 찾지말라고 지시하는 옵션이다. 어플리케이션 프로그래머는 관심을 둘 필요가 없지만 kernel 프로그래머는 관심 있게 볼 수 있는 옵션이다.
== macro 치환
macro
치환에 대해서는 특별히 일어날 만한 에러는 없다. 가끔 문제가 되는 부분이 macro 정의가 한 줄을 넘어선 경우
역슬레쉬('')로 이어져야 하는데 그 소스 파일이 windows용 에디터로 편집 되었으면 parse error가 나는 경우가
있다. 그것은 개행문자(new line character)가 서로 달라서 그런 것인데...음 자세히 이야기하자면 끝이 없으므로
그냥 넘어가도록 해야한다. 또한 macro가 define된 상황에서 macro를 undef하지 않고 다시 define하면 다음과
같은 Warning이 난다.
'xxxx' redefined
macro 치환에서 대한 옵션 두개를 알아보도록 하자.
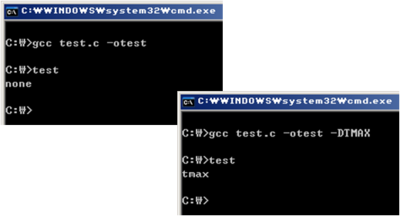
(*) -Dmacro 또는 -Dmacro=defn 옵션
gcc
의 command line에서 macro를 define할 수 있도록 하는 옵션이다. 예를 들어 -D__KERNEL__이라는
옵션을 주면 컴파일 과정 중에 있는 C 언어 소스코드의 맨 처음에 #define __KERNEL__이라고 해준 것과 같이
동작한다. 또한 -DMAXLEN=255라고하면 C 언어 소스코드의 맨 처음에 #define MAXLEN 255 라고 한 것과
동일한 결과를 준다. 선택적 컴파일을 하는 경우에 많이 이용하는 옵션으로 꼭 알아야 할 옵션이다.
(*) -Umacro 옵션
이
옵션은 #undef하고 하는 일이 똑같은데 C 언어 소스코드와는 하등의 관계가 없다. -Dmacro옵션처럼 C 언어 소스코드의
맨처음에 #undef macro를 해주는 것은 아무런 의미가 없기 때문이다.(어짜피 #define은 그 이후에 나올
것이므로...) 이 옵션의 목적은 위의 -Dmacro옵션으로 define된 macro를 다시 undef하고자 할 때 쓰는
옵션이다. 평상시에는 별로 쓸 일이 없는 옵션이지만 그냥 -Dmacro와 같이 짝으로 알아 두길 바란다.
== 선택적 컴파일
#if
시리즈와 #else, #elif, #endif 등으로 선택적 컴파일을 수행할 수 있다. 위에서 설명한 -Dmacro 옵션과 같이
쓰는 경우가 많다. 특별히 설명할 옵션은 없고 #if와 #else, #endif의 짝이 잘 맞아야 한다. 그렇지 않으면 당연히
에러가 발생한다. 단순히 parse error라고 나오는 경우는 드물고, #else, #if 에 어쩌고 하는 에러가 난다. 많이
경우의 수가 있으므로 직접 에러가 발생되도록 코딩을 해보고 확인해 보는 것이 좋다.
== 기타(#line, #error, #pragma)
#line,
#error, #pragma라는 것이 있는지도 모르는 사람들이 꽤 있것이다. 자세한 것은 C 언어 문법 책을 찾아보길 바란다.
#line의 경우 C 언어 소스코드 직접 쓰이는 경우는 거의 없으니까 무시하고 #pragma는 compiler에
dependent하고 gcc에서 어떤 #pragma를 사용하는지도 알 수 없으므로 그냥 넘어가도록 한다. #error의 경우 C
preprocessing 과정에서 강제로 에러를 만드는 지시어이다. 선택적 컴파일 과정에서 도저히 선택되어서는 안 되는 부분에
간혹 쓰인다. 당연히 #error를 만나면 에러가 생긴다. linux kernel 소스코드에서 include 디렉토리를 뒤져
보시면 사용하는 예를 만날 수 있다.
== predefined macro
사
용자가 C 언어 소스코드에서 #define을 하지 않아도 이미 #define된 macro가 있다. ANSI C에서는
__LINE__, __FILE__, __TIME__, __DATE__, __STDC__ 다섯 가지는 이미 define되어 있는
macro로 강제적인 사항이다.(문법책 참조) gcc도 당연히 다섯 가지 macro를 predefine 한다. 뿐만 아니라
GCC의 버전에 대한 macro, architecture에 관한 사항 등을 -Dmacro 옵션 없이도 predefine 한다.
-v 옵션을 실행하여 출력되는 specs파일을 열어보면 쉽게 알 수 있을 것이다.(specs파일이 어떻게 해석되는지는 나도 잘
모른다.)
== 꼭 알아두면 좋은 옵션 한가지
다음과 같이 shell 상에 입력해 보라.(hello.c는 계속되는 그 녀석이다.)
$ gcc -M hello.c
어떤 것이 출력되나? "hello.o: hello.c /usr/include/stdio.h 어쩌구저쩌구"가 출력될 것이다. 어디서 많이 본 듯한 형식 아닌가?
(*) -M 옵션
-M
옵션은 cpp에게 makefile로 만들 수 있는 rule을 만들어 달라고 하는 요청을 보내는 명령이다. file을
include하는 녀석은 cpp이므로 rule은 cpp가 만들 수 있다. 당연히 -Dmacro, -Umacro, -Idir 옵션
등을 같이 사용할 수 있고 그에 따라 결과가 달라질 수도 있다. makefile을 좀 쉽고 정확하게 만들 때 쓰는 옵션이므로
알아두면 좋다. 단점은 default 디렉토리에 있는 보통 사용자는 고칠 수도 없는 파일까지도 만들어 준다는 것이다.
=== C 언어 컴파일 과정
C
언어 컴파일 과정은 gcc라고 하는 frontend가 cc1이라는 다른 실행파일을 호출(fork & exec)하여
수행하게 된다. 사용자가 cc1이라는 실행파일을 직접 실행해야 할 하등의 이유도 없고 권장되지도 않는다. gcc의 입력으로 여러
개의 파일(C 소스 파일, object 파일 등)을 준다고 하더라도 컴파일 과정 중 앞 3단계, 즉 cpp, C 컴파일,
assemble은 각각의 파일 단위로 수행된다. 서로 다른 파일의 영향을 받지 않고 진행된다. 특정 C소스 코드에서
#define된 macro가 다른 파일에는 당연히 반영되면 안된다. header 파일의 존재 의미를 거기서 찾을 수 있다.
이제 C 언어 컴파일 과정이 하는 일을 알아보도록 하자.
== C 언어 컴파일 과정이 하는 일
(1) 입력 : C 언어 소스 코드(C preprocessing된)
(2) 출력 : Assembly 소스 코드
(3) 하는 일 : 컴파일(너무 간단한가?)
C
preprocessing과 마찬가지로 너무 간단하다. 하지만 위의 “컴파일” 과정은 cc1 내부에서는 여러 단계로 나누어져
다음과 같은 순서로 일어난다. Parsing(syntax analysis)이라고 하여 C 언어 소스 코드를 파일로부터 읽어 들여
컴파일러(여기서는 cc1)가 이해하기 쉬운 구조로 바꾸게 된다. 그 다음에 그 구조를 컴파일러가 중간 형태
언어(Intermediate Language)라고 하는 다른 언어로 변환하고 그 중간 형태 언어에 여러가지 최적화를 수행하여
최종 assembly 소스 코드를 만들게 된다.
직접 수행해 보자. 다음과 같이 shell의 command line에 입력하라. 역시 지긋지긋한 hello.c를 이용하도록 한다.
$ gcc -S hello.c
결
과로 출력된 hello.s를 에디터로 열어서 살펴보라 (혹시 위의 command로 hello.s가 만들어 지지 않는다면 gcc
-S -o hello.s hello.c로 하라.). “.”으로 시작하는 assembler directive와 “:”로 끝나는
label명, 그리고 몇 개의 assembly mnemonic이 보이나? Assembly 소스를 읽을 줄 몰라도 그게
assembly 소스 코드구나 생각하면 된다.
(*) -S 옵션
-S 옵션은 gcc의 컴파일 과정 중에서 C 언어 컴파일 과정까지만 처리하고 나머지 단계는 처리하지 말라는 것을 지시하는 것이다. 평소에는 거의 사용하지 않는 옵션이지만 다음과 같은 경우에 유용하게 사용할 수 있다.
(1) 어셈블리 코드가 어떻게 생겼는지 보고 싶은 호기심이 발동한 경우
(2) C calling convention을 알아보거나 stack frame이 어떻게 관리되고 있는 지 보고 싶은 경우
보
통의 경우는 아니지만 사용자가 직접 assembly 코딩을 하는 경우가 종종 있다. 아무래도 사람이 기계보다는 훨씬 똑똑하기
때문에 사람이 직접 assembly 코딩을 해서 최적화를 시도하여 소프트웨어의 수행 시간을 단축시키거나, 아니면 linux
kernel이나 bootloader 등과 같이 꼭 assembly가 필요한 경우가 있다. 이때도 보통의 경우는 소프트웨어의 전
부분을 assembly 코딩하는 것이 아니라 특정 부분만 assembly 코딩을 하고 나머지는 C 언어나 다른
high-level 프로그래밍 언어를 써서 서로 연동을 하도록 한다. 그럼 C 언어에서 assembly 코딩된 함수를 호출할
때(반대의 경우도 마찬가지), 함수의 argument는 어떻게 전달되는 지, 함수의 return 값은 어떻게 돌려지는지 등을
알아볼 필요가 있다. 이렇게 argument와 return 값의 전달은 CPU architecture마다 다르고 그것을 일정한
약속(convention)에 따라서 처리해 주게 된다. 위의 hello.s를 i386용 gcc로 만들었다면 파일 중간에 xorl
%eax,%eax라는 것이 보일 것이다. 자기 자신과 exclusive or를 수행하면 0(zero)이 되는데 이것이 바로
hello.c에서 return 0를 assembly 코드로 바꾼 것이다. 결국 i386 gcc에서는 %eax 레지스터에
return 값을 넣는다는 convention이 있는 것이다.(실제로는 gcc뿐 아니라 i386의 convention으로
convention을 따르는 모든 compiler가 %eax 레지스터를 이용하여 return값을 되돌린다.) argument의
경우도 test용 C 소스를 만들어서 살펴볼 수 있을 것이다. 물론 해당 CPU architecture의 assembly
소스코드를 어느 정도 읽을 수 있는 사람들에게만 해당하는 이야기 이다. stack frame도 비슷한 얘기 쯤으로 알아 두길
바란다.
== Parsing(Syntax Analysis)
위
에서 cc1이 컴파일을 수행하는 과정 중에 맨 첫 과정으로 나온 Parsing에 대해서는 좀더 언급을 한다. Parsing과정은
그야말로 구문(Syntax)을 분석(Analysis)하는 과정이다. Parsing의 과정은 파일의 선두에서 뒤쪽으로 한번 읽어
가며 수행된다. Parsing 중에 컴파일러는 구문의 에러를 찾는 일과 뒤에 수행될 과정을 위해서 C 언어 소스 코드를
내부적으로 다루기 쉬운 형태(보통은 tree형식을 이용)로 가공하는 일을 수행한다. 이 중에 구문의 에러를 찾는 과정은 (1)
괄호 열고 닫기, 세미콜론(;) 기타 등등의 문법 사항을 체크하는 것 뿐만 아니라, (2) identifier(쉽게 말해 변수나
함수 이름 들)의 type을 체크해야 한다.
(1) 괄호 열고 닫기, 세미콜론(;) 기타 등등의 문법 사항에 문제가 생겼을 때 발생할 수 있는 에러가 전에 이야기한 parse error이다. 보통 다음과 같이 발생한다.
>> 파일명과 line number: parse error before x
당연히 에러를 없애려면 ‘x’ 앞 부분에서 괄호, 세미콜론(;) 등을 눈 빠지게 보면서 에러를 찾아 없애야 한다.
(2) type checking
구문 에러를 살필 때 type 체크를 왜 해야 할까? 다음과 같은 예를 보자.
var3 = var1 + var2;
앞 뒤에서 parse error가 없다면 위의 C 언어 expression은 문법적인 문제가 없는가? 하지만 var1이 파일의 앞에서 다음과 같이 정의(definition)되었다면 어떻게 될까?
struct point { int x; int y; } var1;
당연히 ‘+’ 연산을 수행할 수 없다.(C 언어 문법상) 결국은 에러가 난다. 이렇게 identifier(여기서는 var1, var2, var3)들의 type을 체크하지 않고서는 구문의 에러를 모두 찾아낼 수 없다.
만
약 var1과 var3가 파일의 앞에서 int var1, var3;로 정의되어 있고 var2가 파일의 앞에 어떠한
선언(declaration)도 없이 파일의 뒤에서 int var2;로 정의되어 있다면 에러가 발생할까? 정답은 “발생한다”이다.
위에서 언급했듯이 Parsing은 파일의 선두에서 뒤쪽으로 한번만(!!!) 읽으면서 진행하기 때문이다.(모든 C 컴파일러가
그렇게 동작할지는 의심스럽지만 ANSI C 표준에서는 그렇게 되어 있는 것으로 알고 있다. Assembler는 다르다.)
그
렇다면 어떤 identifier를 사용하려면 반드시 파일 중에 사용하는 곳 전에 identifier의
선언(declaration) 또는 정의(definition)가 있어야 한다. 하지만 identifier가 함수 이름일 경우(즉
identifier뒤에 (…)가 올 경우)는 조금 다르다. C 컴파일러는 함수 이름 identifier의 경우는 int를
return한다고 가정하고 Error가 아닌 Warning만 출력한다.(Warning옵션에 따라 Warning조차 출력되지 않을
때도 있다.) 그럼 다음과 같은 소스 코드를 생각해 보자.
int var3, var2;
….
var3 = var1() + var2;
….
struct point var1(void) { … }
위
와 같은 경우도 문제가 생긴다. 맨 처음 var1이라는 함수 이름 identifier를 만났을 때 var1 함수는 int를
return한다고 가정했는데 실제로는 struct point를 return하므로 에러 또는 경고를 발생한다.
결국 권장하는 것은 모든 identifier는 사용하기 전(파일 위치상)에 선언이나 정의를 해 주는 것이다. 다음과 같은 에러 메시지들을 짧막하게 설명해 본다.
파일명 line number: ‘x’ undeclared …. 에러 --> ‘x’라는 이름의 identifier가 선언되어 있지 않았다.
파일명 line number: warning: implicit declaration of function `x' … 경고
--> ‘x’라는 이름의 함수가 선언되어 있지 않아 int를 return한다고 가정했다는 경고(Warning) 메시지이다.
변수나 함수의 선언(declaration)과 정의(definition)에 대해서 알지 못한다면 C 언어 문법책을 찾아서 숙지하길 바란다. 그런 내용이 없다면 그 문법책을 휴지통에 버리길 바란다.
Parsing
과정에는 위의 identifier 에러 및 경고를 비롯한 수많은 종류의 에러와 경고 등이 출력될 수 있다. 에러는 당연히 잡아야
하고 경고도 무시하지 않고 찾아서 없애는 것이 좋은 코딩 습관이라고 할 수 있다. 경고 메시지에 대한 gcc 옵션을 살펴보도록
하자.
(*) -W로 시작하는 거의 모든 옵션
이
옵션들은 어떤 상황 속에서 경고 메시지를 내거나 내지 말라고 하는 옵션이다. -W로 시작하는 가장 강력한 옵션은 -Wall
옵션으로 모든 경고 메시지를 출력하도록 한다. 보통은 -Wall 옵션을 주고 컴파일 하는 것이 좋은 코딩 습관이다.
== Parsing 이후 과정
특
별한 경우가 아닌 이상 Parsing을 정상적으로 error나 warning없이 통과한 C 소스 코드는 문법적으로 완벽하다고
봐야 한다. 물론 논리적인 버그는 있을 수 있지만 이후 linking이 되기 전까지의 과정에서 특별한 error나
warning이 나면 안된다. 그런 경우가 있다면 이제는 사용자의 잘못이 아니라 gcc의 문제로 추정해도 무방하다.
Parsing이후에 assembly 소스 코드가 생성되는데, 당연히 이 과정에는 특별히 언급할 만한 error나 warning은
없다. 그냥 중요한 옵션 몇 가지만 집고 넘어가도록 하겠다.
(*) -O, -O2, -O3 등의 옵션
이
옵션은 컴파일러 최적화를 수행하라는 옵션이다. -O 뒤의 숫자가 올라갈수록 더욱 많은 종류의 최적화를 수행하게 된다. 최적화를
수행하면 당연히 코드 사이즈도 줄어 들고 속도도 빨라지게 된다. 대신 컴파일 수행 시간은 길어진다. 그리고 linux
kernel을 위해 언급하고 싶은 것은 inline 함수들은 이 옵션을 주어야 제대로 inline 된다는 것이다.
(*) -g 옵션
이
옵션은 소스 레벨 debugger인 gdb를 사용하기 위해 debugging 정보(파일명, line number, 변수와 함수
이름들과 type 등)를 assembly code와 같이 생성하라는 옵션이다. 당연히 gdb를 이용하고 싶으면 주어야 한다.
-g 옵션을 주지 않고 컴파일한 프로그램을 gdb로 디버깅하면 C 소스 레벨이 아닌 assembly 레벨 디버깅이 된다. 즉 C
소스 코드에 존재하는 변수 이름, line number 등이 없는 상황에서 디버깅을 해야 한다. 또한 -g 옵션을 -O 옵션과
같이 사용할 수도 있다. 단 그런 경우 최적화 결과, C 소스 코드에 존재하는 심볼(symbol; 쉽게 말해 함수와 변수
이름)중에 없어지는 것들이 발생한다.
(*) 여기서 잠깐
identifier
와 symbol이 모두 “쉽게 말해 함수와 변수 이름”이라고 했는데 어떻게 차이가 날까? 엄밀히 말하면 차이가 조금 있다.
symbol이 바로 “쉽게 말해 함수와 변수 이름”이며 각 symbol은 특정 type과 연계되어 있다. 하지만
identifier는 그냥 “이름” 또는 “인식어”일 뿐이다. 예를 들어 struct point { int x; int y;
};라는 것이 있을 때 point는 symbol은 아니지만 identifier이다. 보통 identifier라는 말은
parsing에서만 쓰인다는 정도만 알아두면 된다.
(*) -p 옵션과 -pg 옵션
profiling
을 아는가? 수행시간이 매우 중요한 프로그램(real time 프로그램이라고 해도 무방할 듯)을 작성할 때는 프로그램의 수행
시간을 함수 단위로 알아야 할 필요가 있는 경우가 많다. 프로그램의 수행 시간을 함수 단위나 더 작은 단위로 알아보는 과정을
profiling이라고 하는데, profiling은 프로그램 최적화에 있어서 중요한 기능을 담당한다. 대부분의 개발 툴이
지원하고 Visual C++에도 존재한다. 옛날 turbo C에는 있었나? 아무튼 gcc도 역시 profiling을 지원한다.
-p 옵션 또는 -pg 옵션을 주면 프로그램의 수행 결과를 특정 파일에 저장하는 코드를 생성해 주게 된다. 그 특정 파일을
적당한 툴(prof또는 gprof 등)로 분석하면 profiling 결과를 알 수 있게 해 준다. 당연히 linux kernel
등에서는 사용할 수 없다.(이유는 특정 파일에 저장이 안되므로…) 초보자들은 이런 옵션도 존재하고 profiling을 할 수
있다는 정도만 알아 두면 좋을 듯 싶다. 나중에 필요하면 좀 더 공부해서 사용하면 된다.
(*) 기타 옵션(-m과 -f시리즈)
중
요한 옵션들이기는 하지만 초보자가 알아둘 필요가 없는 옵션 중에 f또는 m으로 시작하는 옵션들이 있다. f로 시작되는 옵션은
여러 가지 최적화와 assembly 코드 생성에 영향을 주는 architecture independent한
옵션이다.(assembly 코드 생성이 architecture dependent 이므로 정확히 말하면 f로 시작되는 옵션이
architecture independent라고 할 수는 없다.) m으로 시작되는 옵션은 보통 architecture
dependent 하며 주로 CPU의 종류를 결정하는 옵션으로 assembly 코드 생성에 영향을 주게 된다. 하지만 대부분은
초보자는 그런 것이 있다는 정도만 알아두면 되고 특별히 신경 쓸 필요는 없다고 생각된다. m으로 시작되는 옵션 중에
-msoft-float옵션이 있다.(물론 특정 architecture에만 존재하는 옵션이다.) -msoft-float 옵션은
CPU에 FPU(floating point unit)가 없고, kernel에서 floating-point emulation을 해
주지 않을 때 C 소스 코드 상에 있는 모든 floating-point 연산을 특정 함수 호출로 대신 처리하도록 assembly
코드를 생성하라고 지시하는 옵션이다. 이 옵션을 주고 라이브러리를 linking시키면 FPU가 없는 CPU에서도 floating
연산을 할 수 있다.(대신 엄청 느리다. 어찌보면 kernel floating-point emulation보다는 빠를 것 같은데
확실하지는 않다.)
=== Assemble 과정
Assemble
과정은 앞선 과정과 동일하게 gcc라는 frontend가 as라는 실행 파일을 호출하여 수행된다. 그런데 as는 cpp와
cc1과는 달리 gcc 패키지 안에 존재하는 것이 아니라 별도의 binutils라고 하는 패키지에 존재한다. binutils
패키지 안에는 as를 비롯해 linking을 수행하는 ld, library 파일을 만드는 ar, object 파일을 보거나
복사할 수 있는 objdump, objcopy 등 여러 가지 툴이 들어 있다.
이제 Assemble 과정이 하는 일을 알아보도록 하자.
== Assemble 과정이 하는 일
(1) 입력 : Assembly 소스 코드
(2) 출력 : relocatable object 코드
(3) 하는 일 : assemble(너무 간단한가?)
입
력은 당연히 C 언어 컴파일 과정을 거치면 나오는 Assembly 소스 코드이다. Assemble 과정을 거치면 소위
기계어(machine language)라는 결과가 relocatable object 형식으로 나온다.
“relocatable”이라는 말이 어려우면 그냥 object 코드라고 해 두자. 이제 직접 수행해자. shell의
command line에 다음과 같이 입력하면 된다.
$ gcc -c hello.c
결
과는 hello.o라고 하는 파일이 나온다. hello.o는 binary형식의 파일이니깐 editor로 열어봐야 정보를 얻기
힘들다. 당연히 위의 예는 assemble 과정만 수행한 것이 아니라 C preprocessing 과정, C 언어 컴파일 과정,
Assemble 과정을 수행했다. Assemble 과정만 수행하고 싶으면 다음과 같이 입력하면 된다.
$ gcc -c hello.s
역시 hello.o가 생긴다. hello.s는 C 언어 컴파일 과정에서 -S 옵션으로 만들었던 그 파일이다. 별로 관심이 안 생기면 as를 직접 수행할 수도 있다. 다음과 같다.
$ as -o hello.o hello.s
역시 hello.o가 생긴다.
(*) -c 옵션
많
이 쓰는 옵션이다. Assemble 과정까지의 과정만 수행하고 linking 과정을 수행하지 말라는 옵션이다. 여러 개의 C
소스 파일로 이루어진 프로그램을 컴파일 할 때 모든 소스 파일을 assemble 과정까지 수행하고 맨 마지막에
linking한다. 보통은 Makefile을 많이 이용하는데 그 때 많이 쓰이는 옵션이다.
Assemble
과정에서는 더 이상 기억해야 하는 옵션도 없고 이게 끝이다. C 언어 컴파일 과정에서 말한 바대로 C 언어 컴파일 과정이 끝난
C 소스 파일은 문법적으로 완전하다고 볼 수 있으므로 assemble 과정에서 Error나 Warning 나는 경우는 없다.
만약 Error나 Warning이 나는 경우가 있다면 gcc의 inline assemble을 이용했을 때, 그 inline
assemble 소스 코드에 있는 문제 때문에 생길 수 있다. 안타깝지만 error나 warning 메시지가 나온 다면 C 소스
파일과 line number 정보는 없다. 잘 알아서 처리하는 수 밖에 다른 방법은 없는 것 같다. inline assemble
같은 것을 사용하지 않았는데도 error나 warning이 난다면 gcc의 버그라고 생각해도 무방하다.
== relocatable object 코드 파일 내용
어
떤 정보가 object 파일 안에 들어있을까? 당연히 code와 data가 들어 있다. C 컴파일 과정에서 C 언어 함수 안에
있는 내용들이 assembly mnemonic 들로 바뀌었고 그것이 assemble되어 기계어(machine language)가
되었을 것이다. 그 부분이 code를 이룬다. C 언어 소스 코드에 있는 나머지는 전역 변수(external variable)와
정적 변수(static variable)들이 data를 이룰 것이다. 또한 문자열 상수를 비롯한 상수도 data에 들어 있다.
또한 프로그램 수행에 쓰이지는 않고 단순한 정보로서 들어 있는 data들도 있다. 예를 들어 -g 옵션을 주고 컴파일 하면
프로그램의 디버깅 정보(변수, 함수 이름, C 소스 파일이름, line number 등)가 data에 속한다고 볼 수 있다.
그런데 code와 data가 무질서하게 섞여 있는 것은 아니고 section이라고 불리우는 단위로 서로 구분되어 저장되어 있다.
Code는 text section에 들어 있고, data는 성격에 따라 data section, bss section,
rodata section 등에 나누어져 저장되어 있다.(text, data, bss, rodata 등의 section 이름은
그냥 관습적인 것이다.) 아무튼 section 이야기는 이 정도만 우선 알아두면 될 듯 싶다.
== Symbol 이야기
relocatable
object code안에 code와 data가 들어 있다고 했는데, 아주 중요한 것을 빠뜨렸다. 이 이야기는 linking
과정을 이해하기 위해 꼭 필요한 부분이므로 반드시 읽어야 할 것이다. 우선 Symbol이 무엇인지 알 것이다. C 언어 컴파일
과정에서 identifier와 함께 설명했는데 잠시 다시 말씀하자면 Symbol은 함수와 변수 이름이다. 변수 중에 특히
관심두어야 할 것 들은 자동 변수(?,auto variable)들이 아닌 전역 변수(external variable)와 정적
변수(static variable)이다. 자동 변수는 함수의 stack frame에 존재하는 변수이기 때문에 현재 stack
pointer(sp, 보통의 CPU의 register중에 하나)에 대한 offset으로 표현된다. 즉 현재 함수에서 자동
변수(auto variable)를 access(read/write)하고 싶으면 sp+상수의 어드레스를 access하면 된다.
하지만 전역 변수와 정적 변수는 그냥 32bit(32bit CPU기준) 어드레스를 읽어야 한다. stack pointer랑은
전혀 관계 없다. 아무튼 여기서 관심을 두는 Symbol은 함수, 전역 변수와 정적 변수의 이름이라고 할 수 있다.
이제
생각해 볼 것은 C 언어 소스 파일을 C preprocessing, C 언어 컴파일, assemble 과정을 거치면 완전한
기계어로 바꿀 수 있느냐 하는 점이다. 완전히 기계어로 바꿀 수 있을까? C 언어 소스 파일 하나로 이루어지는 프로그램이라면
완전히 기계어로 바꾸는 것이 가능하겠지만 일반적으로는 불가능 하다. 다음과 같은 예제를 살펴보자.
int func3(void); /* func3 선언 */
extern int mydata; /* mydata 선언 */
int func2(void) /* func2 정의 */
{
….
}
int func1(void) /* func1 정의 */
{
int i;
…..
func2();
…..
func3();
….
i= mydata+3;
…..
}
-- end of test1.c
-- start of test2.c
int mydata = 3; /* mydata 정의 */
int func3(void) /* func3 정의 */
{
…..
} |
위
의 예제를 컴파일 한다고 생각해보자. test1.c에서 func1()의 내용을 기계어로 바꾸고 싶은데 func2()를 호출하는
시점에서는 별로 문제가 안된다. func2()는 같은 소스 코드 내에 존재하고 func2()를 호출하는 instruction과
func2()의 실제 위치(어드레스)의 차이를 계산해 낼 수 있으므로 상대 어드레스를 이용하는 함수 호출
instruction으로 완전히 기계어로 바꿀 수 있다. 그런데 문제는 func3()를 호출할 때는 func3()의 실제
위치(address)를 계산할 수 없다는 문제점이 있다. 당연히 동일한 파일에 존재하는 함수가 아니므로 그 함수가 존재하게 될
어드레스를 계산할 수 없다. 어드레스를 모르는데 함수 호출 instruction을 완전히 만들 수 있을까? 만들 수 없다.
당연히 전역 변수 mydata를 access하는 부분도 마찬가지로 mydata의 어드레스를 모르므로 완전히
instruction으로 바꿀 수 없다. 그럼 어떻게 해야 될까?
그때 assembler는 그냥 함수 어드레스 없는
함수 호출 instruction을 기계어로 바꾸어 놓는다. 그런 다음에 그 instruction에 “func3()를
호출한다”라는 표지를 붙여 놓는다. 그럼 그 후의 과정(linking)에서 func3()의 address를 계산했을 때 그 빈
공간을 채워 넣게 된다. mydata와 같은 전역 변수도 마찬가지로 동작한다. test1.c을 컴파일할 때는 “func3()”,
“mydata” 라는 표지를 사용해야 한다. 그럼 test2.c를 컴파일 할 때는 무엇이 필요할까? 상식적으로 생각하면
“func3()”, “mydata”가 여기 있다라는 정보를 가지고 있어야한다.
정리하면 object 파일 안에는 그
object 파일에 들어있는 symbol들(test1.o에서는 func1과 func2, test2.o에서는 func3와
mydata)에 대한 정보가 들어있고, 그 object 파일이 reference하고 있는 symbol들(test1.o에서
func3와 mydata 사용)에 대한 정보가 들어 있다.
== Relocatable의 의미
위
에서 object 코드라고 하지 않고 relocatable object 코드라고 지칭했는데 relocatable이 뜻하는 것을
잠시 집고 넘어 가자. Relocatable을 사전에서 찾아보면 “재배치가 가능한” 정도의 뜻이다. “재배치가 가능한” 이라는
의미는 상당히 모호하다. 좀 더 구체적으로 말하자면 위에서 설명된 symbol들의 절대 어드레스가 정해지지 않았다는 뜻이다. 즉
test1.c의 func1()이 절대 어드레스 0x80000000에 존재해야 한다라고 정해지지 않고 어떤 절대 어드레스에
존재해도 관계 없다는 뜻이다. 그런데 이 말과 헷갈리는 말이 한가지 더 있는데 그것은 position independent
code이다. C 언어 컴파일 과정에서 설명한 옵션중에 -f 시리즈가 있었다. 그 중에 -fpic라는 position
independent code를 만들라고 강제하는 옵션이 있다. position independent code도 역시 절대
어드레스상에 어느 위치에 있어도 무방한 code를 지칭한다. 하지만 두 가지는 분명 차이가 있는데, 그냥 넘어가기로 하자. 쉽게
relocatable은 절대 어드레스가 결정되지 않았다는 뜻, 그러나 position independent code와는 다른
말이다.
=== Linking 과정
Linking
과정은 ld라고 하는 실행파일이 담당하고 있다. Assemble을 담당하는 as와 마찬가지로 binutils 패키지의
일부분이다. 보통 어플리케이션을 컴파일하는 경우에는 gcc(실행파일)를 이용하여 ld를 호출하나, 특별한 경우에 있어서는 ld를
직접 수행하여 linking을 하는 경우가 종종 있다.
== Linking 과정이 하는 일
(1) 입력 : 하나 이상의 relocatable object 코드 와 library
(2) 출력 : 실행파일(executable) 또는 relocatable object 코드
(3) 하는 일 : symbol reference resolving & location
Linking
과정은 하나 또는 그 이상의 object 파일과 그에 따른 library를 입력으로 받는다. 출력은 보통의 경우는
실행파일(executable file)이지만, 경우에 따라서 object 파일을 생성하게 할 수도 있다. 여러 개의 object
파일을 합쳐서 하나의 object 파일로 만드는 과정을 partial linking이라고 부르기도 한다. Linking 과정이
하는 일은 symbol reference resolving하고 location이라고 했는데, 저도 정확한 단어를 적은 것인지
의심스럽다. 정확한 용어를 사용한다면 좋겠지만 그렇지 못하더라도 내용을 정확히 이해하는 것이 중요하니깐 내용에 대해서 살펴보도록
하겠다.
== symbol reference resolving
어
떤 C 소스 파일에서 다른 파일에 있는 함수와 전역 변수(symbol)에 대한 참조(reference)를 하고 있다면
assemble 과정에서 완전한 기계어로 바꿀 수 없다.(실제로는 같은 소스 파일에 있는 전역 변수를 참조하는 것도 보통의
경우, 완전한 기계어로 바꿀 수 없다.) 그 이유는 당연히 assemble 까지의 과정은 단일 파일에 대해서만 진행되고, 다른
파일에 있는 해당 함수와 전역 변수의 address가 상대적이든 절대적이든 결정될 수 없기 때문이다. 따라서 완전히 기계어로
바꿀 수 없는 부분은 그대로 “공란”으로 남겨두고 표시만 해 두게 된다.
Linking 과정에서 그 “공란”을 채워
넣게 된다. 그 과정을 보통 “resolve한다”라고 말한다. 어떻게 할까? 당연히 실행 파일을 이루는 모든 object 파일을
입력으로 받기 때문에 object 파일들을 차곡 차곡 쌓아 나가면(아래 location 참조) object 파일 안에 있는 모든
symbol(함수나 전역 변수 이름)의 address를 상대적이든 절대적이든 계산할 수 있다. 이제 각 symbol의
address가 계산되었으므로 표시가 남아 있는 “공란”에 해당하는 symbol의 address를 잘 넣어주면 된다.
linking
과정에서 나올 수 있는 에러는 대부분 여기에서 발생한다. 표시가 남아 있는 “공란”을 채울 수 없는 경우가 있다. 크게 두
가지로 나누어지는데, 우선 reference하고 있는 symbol을 찾을 수 없는 경우와 reference하고 있는
symbol의 정의가 여러 군데에 있는 경우이다.
>> object파일명: In function ‘func’:
>> object파일명: undefined reference to ‘symbolname’
위
의 에러 메시지는 함수 func 안에서 사용되고 있는 symbolname이란 이름의 symbol이 어디에도 정의되지 않아서
“공란”을 채울 수 없다는 뜻이다. 당연히 symbolname을 잘못 입력하였던지 아니면 그 symbol이 속해있는 object
파일이나 library와 linking되지 않았기 때문이다.
>> object파일명1: multiple definition of ‘symbolname’
>> object파일명2: first defined here
위
의 에러 메시지는 symbolname이란 이름의 symbol이 여러 번 정의되고 있다는 뜻이다. object파일1에서 정의가
있는데 이미 object파일2에서 정의된 symbol이므로 그 symbol을 reference하고 있는 곳에서 정확하게
“공란”을 채울 수 없다는 뜻이다. 당연히 두 symbol중에 하나는 없애거나 static으로 바꾸거나 해야 해결될 것이다.
== location(용어 정확하지 않을 수 있음)
이
전 까지 object 코드를 모두 relocatable이라고 표현했다. 아직 절대 address가 결정되지 않았다는 의미로
사용된다.(position independent code와는 다른 의미) object 코드의 절대 address를 결정하는
과정이 “location”이다. Symbol reference resolving 과정에서 입력으로 받은 모든 object
파일들을 차곡 차곡 쌓아 나간다고 했다. 그런데 object 파일이 무슨 벽돌도 아닌데 차곡 차곡 쌓는 다는 것이 말이 되나?
여기서 쌓는 다는 말을 이해하기 위해서 다음과 같은 그림(?)을 살펴 보도록 하자.
많은 object code들
----------------- address(0xAAAAAAAA+0x5000)
test2.o(size 0x3000)
----------------- address(0xAAAAAAAA+0x2000)
test1.o(size 0x2000)
----------------- address(0xAAAAAAAA)
절
대 address 0xAAAAAAAA에 test1.o의 내용을 가져다 놓는다. test1.o의 크기(파일 크기와는 의미가 조금
다르지만 그냥 무시하고 파일 크기라고 생각하기 바람)가 0x2000이므로 다음에 test2.o를 쌓을 수 있는 address는
0xAAAAAAAA+0x2000가 된다. 그곳에 다시 test2.o를 쌓고 또 test2.o의 크기를 보고 새로운 address
계산하고 또 object 코드 쌓고, 계속 반복이다. 이렇게 쌓을 때 초기 절대 address 0xAAAAAAAA가 무슨 값을
가지게 되면 모든 object 파일에 있는 symbol의 절대 address도 계산해 나갈 수 있을 것이다. 그걸로 symbol
reference를 resolve하게 된다. 그 초기 절대 address 0xAAAAAAAA의 값을 정하는 것을
location이라고 한다. 그럼 왜 절대 address를 결정해야 할까? 꼭 그래야 할 필요는 없지만 CPU의
instruction이 대부분의 경우 절대 address를 필요로 하는 경우가 많기 때문이라고 할 수 있다.
(주의) object 를 쌓는 것은 위의 예처럼 단순하지는 않다. 실제로는 object 전체를 쌓지 않고 object안에 있는 section별로 쌓게 된다.
그럼 이제 직접 수행해 보자.
$ gcc -o hello hello.o
object
파일이 하나라서 너무 단순하다고 생각하는가? 물론 hello.o 하나만 command line에 나타나지만 실제로는 조금 많은
object 파일이 linking되고 있다. (아래에서 좀더 자세하게 설명한다.) 지겹지만 hello를 실행해 보라. 제대로
동작하는가? 제대로 동작한다면 그 사이 어떤 일이 벌어졌을까? 그 사이에 벌어진 일을 간단히 적어보면 다음과 같다. shell이
fork() 시스템콜을 호출하고 자식 process는 exec() 시스템콜을 통해 hello라는 파일 이름을 kernel에
넘긴다. kernel에서는 hello파일을 보고 linking할 때 location된 address(여기서는 absolute
virtual address 이다.)상의 메모리로 hello 파일을 복사하고 PC(program counter)값을 바꾸면
수행되기 시작한다.
(주의) 실제로 위의 hello가 수행되는 과정은 많은 생략과 누락이 있다. 실제로는 hello
파일을 완전히 메모리로 복사하는 것도 아니고, dynamic linking & loading 등의 개념이 완전히 빠져
있지만 그냥 이해하기 쉽게 하기 위해서 간단하게 적어 본 것이다.
= library
hello.o
를 linking하여 hello라고 하는 실행파일을 만드는데 command line에서는 아무것도 없지만 library가 같이
linking되고 있다. 그것은 지극히 당연하다. hello.c의 main함수에서 printf함수를 호출(linking이니깐
참조 혹은 reference라고 해야 좋겠다.)하고 있는데 printf함수 자체는 소스 중에 그 어디에도 없다.(물론
stdio.h에 printf함수의 선언은 있습니다만 정의는 어디에도 없다.) 잘 알다시피 printf함수는 C standard
library 안에 있는 함수이다. C standard library가 같이 linking되었기 때문에 제대로 동작하는
hello 실행파일이 생긴 것이다.
library라는 것은 아주 간단한 것이다. relocatable object
파일들을 모아 놓은 파일이다. 소스로 제공할 수도 있으나, 그러면 매번 cpp, c 컴파일, assemble 과정을 거쳐야
하므로 컴파일 시간이 매우 증가하게 된다. 그래서 그냥 relocatable object 파일로 제공하는 것이 컴파일 시간
단축을 위해서 좋다. 그런데 필요한 relocatable object 파일이 너무 많으면 귀찮으니까 그것을 묶어서 저장해 놓은
녀석이 바로 library라고 할 수 있다.
Linux를 비롯한 unix 계열에서는 대부분의 library 파일의
이름이 lib로 시작된다. 확장자는 두 가지가 있는데, 하나는 .a이고 또 하나는 .so입니다.(뒤에 library 버전 번호가
붙는 경우가 많다.) .a로 끝나는 library를 보통 archive형식의 library라고 말하며 .so로 끝나는
library를 보통 shared object라고 부른다. /lib 디렉토리와 /usr/lib 디렉토리에 가면 많이 볼 수
있다.
archive library 안에 있는 symbol를 reference하게 되면 library중에 해당
부분(object 파일 단위)을 실행 파일 안에 포함시켜 linking을 수행한다. 즉, 해당 object 파일을 가지고
linking을 수행하는 것과 동일한 결과를 가진다. 보통 이런 linking을 static linking이라고 부른다.
그
런데 시스템 전체에 현재 수행되고 있는 실행파일(실행파일이 수행되고 있는 하나의 단위를 process라고 한다.)들에서
printf함수를 사용하고 있는 녀석들이 매우 많으므로 그것이 모두 실행 파일에 포함되어 있다면 그것은 심각한 메모리 낭비를
가져온다는 문제점을 가지고 있다. 그래서 생각해 낸 것이 dynamic linking이라는 개념이다. 예를 들어 실행파일이
printf함수를 사용한다면 실행파일이 메모리로 loading될 때 printf가 포함되어 있는 library가 메모리 상에
있는 지 검사를 해 보고 있으면 reference resolving만 수행하고, 아니라면 새로 loading과 reference
resolving을 하게 된다. 그렇게 되면 printf가 포함되어 있는 library는 메모리 상에 딱 하나만
loading되면 되고 메모리 낭비를 막을 수 있다. 그런 일을 할 수 있도록 도입된 것이 shared object 이다. MS
Windows쪽의 프로그래밍을 하시는 사람이라면 DLL과 동일한 개념이라고 보면 된다.
그런 shared object를
이용하여 dynamic linking을 하면 실행파일의 크기가 줄어든다. 반면에 당연히 실행파일이 메모리에 loading될 때는
reference resolving을 위해서 CPU의 연산력을 사용한다. 하지만 MS Windows의 DLL과는 달리
shared object 파일과 static linking을 할 수도 있다.(반대로 archive library를 이용하여
dynamic linking을 수행할 수는 없다.)
(*) -static 옵션
dynamic
linking을 지원하고 있는 시스템에서 dynamic linking을 수행하지 않고 static linking을 수행하라는
옵션이다. dynamic linking을 지원하고 있는 시스템에서는 dynamic linking이 default 이다.
직접 수행해 보자.
$ gcc -o hello_static -static hello.o
실행파일 hello, hello_static 을 수행하면 결과는 똑같다. 파일의 크기를 비교해 보면 차이가 난다는 것을 알 수 있을 것이다.
/lib,
/usr/lib에는 엄청 많은 library 파일들이 존재한다. 그럼 linker가 찾아야 하는 symbol을 모든
library 파일에 대해서 검사를 하는 것일까? CPU하고 HDD가 워낙 빠르면 그래도 무방하겠지만, 그렇게 하지
않는다.(“사용자가 쉽게 할 수 있는 일을 컴퓨터에게 시키지 말라.”라는 컴퓨터 사용 원칙이다.) 우선 gcc는 기본적인
library만 같이 linking을 하게 되어 있다. 나머지 library는 사용자의 요구가 있을 때만 같이 linking을
시도하도록 되어 있다. 그럼 기본적인 library가 무엇인지 알아야 하고 gcc에게 사용자의 요구를 전달할 옵션을 있어야 할
것이다. 기본적인 library는 당연히 C standard library 이다. C standard library의 이름은
libc.a또는 libc.so 이다. 최근의 linux 머신은 /lib/libc.so.6 이라는 파일을 찾아 볼 수 있을 것이다
(symbolic link되어 있는 파일이다). 그리고 libgcc라고 하는 것이 있는데… 생략하고. 이제 옵션을 알아보자.
(*) -nostdlib 옵션
이
름에서 의미하는 바대로 standard library를 사용하지 말고 linking을 수행하라는 뜻이다. 실제로는
standard library 뿐 아니라 startup file이란 녀석도 포함하지 않고 linking이 수행된다.
startup file에 대해서는 좀 있다가 알아보도록 하겠다.
(*) -l라이브러리이름 옵션
특
정 이름의 library를 포함하여 linking을 수행하라는 뜻이다. 예를 들어 -lmyarchive라고 하면
libmyarchive.a(또는 libmyarchive.so)라는 library파일과 같이 linking을 수행하는 것이다.
library 파일 이름은 기본적으로 lib로 시작하니깐 그것을 빼고 지정하도록 되어 있다.
library에
대해서 또 하나의 옵션을 알아야 할 필요가 있다. 다름 아닌 “어느 디렉토리에서 library를 찾는가”이다. 모든
library가 /lib와 /usr/lib에 있으라는 보장이 없다. 그 디렉토리를 정하는 방법은 두 가지 인데
LD_LIBRARY_PATH라고 하는 이름의 환경 변수를 셋팅하는 방법이 있고 또 한 가지는 gcc의 옵션으로 넘겨 주는 방법이
있다.
(*) -Ldir 옵션
library
파일을 찾는 디렉토리에 “dir”이란 디렉토리를 추가하라는 옵션이다.(-Idir 옵션처럼 -L과 dir을 붙여서 적습니다.)
예를 들어 -L/usr/local/mylib 라고 하면 /usr/local/mylib라는 디렉토리에서 library 파일을 찾을
수 있게 된다.
== entry 이야기
application
을 작성하고 compile, linking 과정이 지나면 실행 파일이 만들어진다. 그리고 그 실행 파일이 수행될 때는 메모리로
load되어 수행이 시작된다는 사실을 알고 있다. 여기서 한가지 의문이 생기는데, “과연 코드의 어떤 부분에서 수행이
시작되는가?”이다. 답이 너무 뻔한가? main함수부터 수행된다고 답할 것인가? 다소 충격적이겠지만 “땡”이다. main함수부터
수행되지 않고 그전에 수행되는 코드가 존재한다. 그 먼저 수행되는 코드에서 하는 일은 여러 가지가 있는데 그냥 건너 뛰도록
하겠다. 아무튼 그 코드에서 main함수를 호출해 주고 main함수가 return하면 exit 시스템호출을 불러 준다. 그래서
main이 맨 처음 수행되는 것처럼 보이고 main이 return하면 프로그램 수행이 종료되는 것이다. 그럼 그 코드는 어디
있을까? 시스템에 따라서 다르겠지만 일반적으로 /lib혹은 /usr/lib 디렉토리에 crt1.o라는 이름의 object 파일이
있는데 그 object 파일 안에 있는 _start라는 이름의 함수(?)가 맨 먼저 수행되는 녀석이다. 결국 보통
application의 entry는 _start함수가 된다.
그럼 crt1.o object 파일 역시 같이
linking 되어야 한다. gcc를 이용해 linking을 수행할 때 command line에 아무 이야기를 해주지 않아도
자동으로 crt1.o 파일이 함께 linking 된다. 실제로는 crt1.o 뿐 아니라 비슷한 crt*.o 파일들도 같이
linking 된다. 그렇게 같이 linking 되고 있는 object파일들을 startup file이라고 부르는 것
같다.(-nostdlib 옵션 설명할 때 잠시 나왔던 startup file이 바로 이 녀석들이다.) 그럼 ld는
_start파일이 entry인지 어떻게 알고, 다른 이름의 함수를 entry로 할 수는 없는것일까? 그것에 대한 해답은 아래
linking script부분에서 해결될 것이다.
== 실행 파일에 남아 있는 정보
linking
의 결과 실행파일이 생겼는데, 보통 linux에서는 실행파일 형식이 ELF라는 포멧을 가진다.(linux 시스템에 따라 다를 수
있다.) ELF는 Executable and Linkable Format의 약자이다. 보통 linux 시스템에서의
relocatable object 파일의 형식도 ELF이다. 실제로 실행파일과 relocatable object 파일과는 조금
다른 형식을 가진다. 암튼 그건 상식으로 알아두고, 그럼 실행파일에 있는 정보는 무엇일까?
이제까지의 알아낸 정보들을
모두 종합하면 알 수 있다. 우선 실행 파일이라는 녀석이 결국은 relocatable object 를 여러 개 쌓아놓은
녀석이므로 원래 relocatable object 파일이 가지고 있던 code와 data 정보는 모두 남아있을 것이다. 그리고
entry를 나타내는 address가 있어야 수행을 할 수 있을 것이다. 또, dynamic linking을 했을 경우 관련된
shared object 정보도 남아있어야 한다.
실행 파일 속에 남아있는 data는 relocatable
object에 있는 data처럼 프로그램 수행에 필요한 data가 있고 그냥 실행 파일을 설명하는 정보로서의 data가 있다.
예를 들어 -g 옵션을 주고 컴파일한 실행파일에서 디버깅 정보들은 실행과는 전혀 관계 없다. 따라서 그러한 정보들은 실행 파일
수행시에 메모리에 load될 필요도 없다.(load하면 메모리 낭비니깐) 실행 파일 속에 남아있는 code와 data는
relocatable object 처럼 특별한 단위로 저장되어 있다. ELF 표준에서는 segment라고 부르는데 보통의 경우는
object 파일처럼 section이라는 말이 쓰인다. reloctable object 파일과 마찬가지로 code는 text
section에 저장되고 프로그램 수행 중에 필요한 data가 성격에 따라 나누어져 data, rodata, bss
section이란 이름으로 저장되어 있다. 그 section단위로 메모리로 load될 필요가 있는지에 대한 flag정보가 있고
각 section이 load될 address(location과정에서 정해진다.)가 적혀 있어야 정확하게 loading을 할 수
있다.
기타로 symbol reference resolving이 끝났는데도 ELF형식의 실행파일은 보통의 경우 많은
symbol 정보를 그냥 가지고 있는 경우가 있다. symbol 정보 역시 수행에는 하등 관계가 없으므로 없애도 되는데,
strip이라고 하는 binutils안에 있는 tool로 없앨 수 있다.
== linking script
흠
이제 좀 어려운 이야기를 할 차례이다. Location과정에서 어떤 절대 address를 기준으로 각 section들을 쌓는지,
그리고 entry는 어떤 symbol인지에 대한 정보를 linker에게 알려줄 필요가 있다. 보통 application의 경우는
시스템 마다 표준(?, 예를 들어 entry는 _start 다 하는 식)이 있는지라 별로 문제될 것은 없는데,
bootloader나 kernel을 만들 때는 그런 정보를 사용자가 넘겨 주어야 할 필요가 있다. 그런 것들을 ld의
command line argument로 넘길 수도 있지만 보통의 경우는 linking script라고 하는 텍스트 형식의 파일
안에 저장하여 그 script를 참조하라고 알려준다. (아무래도 command line argument로 넘겨 줄 수 있는
정보가 한계가 있기 때문이라고 생각이 든다. location과 entry에 관한 내용 중에 ld의 command line
argument로 줄 수 있는 옵션이 몇가지 있으나 한계가 있다.) ld의 옵션 -T으로 linking script 파일 이름을
넘겨 주게 된다.(gcc의 옵션 아님) linux kernel source를 가지고 있는 사람은 arch/*/*.lds 파일을
한번 열어 보길 바란다. 그게 linking script고, 초기 절대 address 하고 section 별로 어떻게 쌓으라는
지시어와 entry, 실행 파일의 형식 등을 적어 놓은 내용이 보일 것이다. 물론 한 줄 한 줄 해석이 된다면 이런 글을 읽을
필요가 없다. 그 script를 한 줄 한 줄 정확히 해석해 내려면 GNU ld manual 등을 읽어야 할 것이다.
== linux의 insmod
linux
kernel을 구성하고 device driver 등은 linux kernel module(이하 module) 형식으로
run-time에 올릴 수 있다는 것을 알고 있을 것이다. module을 run-time에 kernel에 넣기 위해서 사용하는
명령어가 insmod이다.(modprobe도 가능) 이 module 이라는 것이 만들어 지는 과정을 잘 살펴 보면 gcc의
옵션중에 -c옵션으로 컴파일만 한다는 것을 알 수 있다. 확장자는 .o를 사용한다. relocatable object 파일이고,
ELF형식이다. 그럼 이 module이 linux kernel과 어떻게 합쳐질까? 당연히 linking 과정을 거쳐야 된다.
일종의 run-time linking 이다. 당연히 module은 kernel내의 많은 함수와 전역 변수를 참조한다. 그렇지
않다면 그 module은 linux kernel의 동작과는 전혀 관계 없는 의미 없는 module이 될것이다. 그럼 참조되고
있는 symbol을 resolving하기 위해서는 symbol의 절대 address를 알아야한다 . 그 내용은 linux
kernel 내부에 table로 존재한다. /proc/ksyms라고 하는 파일을 cat 해보면 절대 address와 symbol
이름을 살펴볼 수 있을 것이다. 살펴보면 알겠지만 생각보다 적은 양이다. 적은 이유는 그 table이 linux kernel
source에 있는 전역 symbol의 전부를 포함한 것이 아니라 kernel source 내부나 module 내부에서
EXPORT_SYMBOL()과 같은 특별한 방법으로 선언된(?, 이 선언은 C 언어 문법의 declaration과는 다르다.)
symbol들만 포함하기 때문이다. 다른 전역 symbol 들은 module 프로그래밍에 별 필요가 없다고 생각되어 지는
녀석들이기 때문에 빠진 것이다. 따라서 EXPORT_SYMBOL()등으로 선언된 symbol들만 사용하여 module을 작성해야
한다. 당연히 linking 과정을 거치기 때문에 앞서 설명한 linking에서 발생할 수 있는 에러들이 발생할 수 있다. 제일
많이 발생할 수 있는 것은 역시 undefined reference 에러이다. gcc의 에러와는 조금 다른 메시지가 나오겠지만
결국은 같은 내용이다.
== map 파일
linking
과정을 끝내면 당연히 모든 symbol에 대한 절대 address가 정해지게 된다. 그 정보를 알면 프로그램 디버깅에 도움이 될
수도 있으니 알면 좋을 것이다. ld의 옵션중에 '-Map 파일이름'이라는 옵션이 있는데 우리가 원하는 정보를 문서 파일
형식으로 만들어 준다. 그 파일을 보통 map 파일이라고 부른다. symbol과 address 정보 말고 section에 대한
정보도 있고 많은 정보가 들어 있다.
linux kernel을 컴파일을 하고 나면 나오는 결과 중에
System.map이라는 파일이 있는데 이 녀석이 바로 ld가 만들어 준 map 파일의 내용 중에 symbol과 symbol의
절대 address가 적혀 있는 파일이다. linux kernel panic으로 특정 address에서 kernel이 죽었다는
메시지가 console에 나오면 이 System.map 파일을 열어서 어떤 함수에서 죽었는지 알아볼 수도 있다.
== 옵션 넘기기
gcc
의 이야기 맨 처음에 gcc는 단순히 frontend로 command line으로 받은 옵션을 각 단계를 담당하고 있는
tool로 적절한 처리를 하여 넘겨준다고 말했었다. 위에서 나온 ld의 옵션 -T와 -Map 과 같은 옵션은 gcc에는 대응하는
옵션이 존재하지 않는다. 이런 경우 직접 ld를 실행할 수도 있고 gcc에게 이런 옵션을 ld에게 넘겨 주라고 요청할 수 있다.
하지만 application을 컴파일할 때는 ld를 직접 실행하는 것은 조금 부담이 되므로, gcc에 옵션을 넘기라고 요청하는
방법이 조금 쉽다고 볼 수 있다. 그런 경우 사용되는 것이 -Wl 옵션인데 간단히 이용해 보도록 하자.
$ gcc -o hello -static -Wl,-Map,hello.map hello.c
그럼 hello.map이라는 매우 큰 문서 파일이 만들어진다. 한번 살펴 보도록 하자.(-static 옵션을 안 넣으면 살펴볼 내용이 별로 없을까봐 추가했다.)
실제로는 -Wl 옵션처럼 as에게도 옵션을 넘겨 줄 수 있는 -Wa와 같은 옵션이 있는데 쓰는 사람을 본 적이 없다.